正規表現とは
さまざまな文字の連続(文字列)を検索条件等の汎用的なパターンで表現するためのひとつの方法。
A regular expression (shortened as regex or regexp) is a sequence of characters that specifies a match pattern in text.(Wikipediaより)
正規表現の用途
正規表現は、さまざまなプログラミング言語やテキストエディタ、コマンドラインツールなどで利用され、以下のような多岐にわたる用途があります。
検索と抽出
- 特定の文字列の検索: 大量のテキストの中から、特定のキーワードやフレーズを探し出すことができます。
- データの抽出: ログファイルから特定のエラーメッセージを抽出したり、WebページからメールアドレスやURLを抜き出したりする際に使われます。例えば、HTMLからすべての画像URLを抽出するといったことが可能です。
- 構造化されたデータのパース: 設定ファイルやCSVファイルなどから、特定のフィールドのデータを効率的に取り出すことができます。
置換と編集
- 文字列の置換: テキスト内の特定のパターンに一致する文字列を一括で別の文字列に置き換えることができます。例えば、すべての「旧姓」を「新姓」に変換したり、特定の記号を削除したりするのに便利です。
- フォーマットの統一: 不規則なデータ形式を統一された形式に変換する際に利用されます。例えば、日付の表記を「YYYY/MM/DD」に統一するなどです。
検証とチェック
- 入力値の検証: ユーザーが入力したデータが特定の形式(例:メールアドレス、電話番号、パスワードの強度など)に沿っているかをチェックするために使われます。これにより、不正なデータや誤った形式のデータがシステムに登録されるのを防ぎます。
- データのクリーンアップ: 不要な空白文字や特殊文字を削除するなど、データを整形するのに役立ちます。
その他
- 構文解析: プログラミング言語のコンパイラやインタープリタで、コードの字句解析を行う際に正規表現が利用されることがあります。
- ログ解析: システムのログファイルを分析し、特定のアクティビティや問題を特定するのに役立ちます。
正規表現一覧
| 正規表現 | 意味 | マッチする文字列 |
|---|---|---|
| [123] | 1か2か3にマッチ | 1か2か3のいずれか1文字 |
| [0-9] | 数字にマッチ | 0123456789のいずれか1文字 |
| [a-z] | 英字(小文字)にマッチ | abcd・・・zのいずれか1文字 |
| [a-zA-Z0-9] | 数字・英字にマッチ | 数字・英字のいずれか1文字 |
| [都道府県] | 都か道か府か県にマッチ | 都か道か府か県のいずれか1文字 |
| [^0-9] | 数字以外にマッチ | abcxyzABCXYZ!#などの1文字 |
| [^ア-ン] | カタカナではない文字 | カタカナではない文字1文字 |
| \d | [0-9] | |
| \w | [a-zA-Z0-9_] | |
| \D | \d以外 | |
| \W | \w以外 | |
| (black|red|blue) pen | 選択 | black pen または red pen または blue pen |
| c.t | 任意の文字 | cat cot cutなど |
文字列 のさまざまな側面を確認する
REGEXTEST 関数は、テキストの任意の部分がパターンと一致するかどうかを決定します。
REGEXTEST(text, pattern, [case_sensitivity])
text : 対象テキスト
pattern : 正規表現
case_sensitivity : 大文字小文字か
例 (セルA4からA10までの文字列)
西暦2024年、西暦2025年、・・・、西暦2028年
| 数式 | 問い |
| セルB4 =REGEXTEST(A4,”西暦202[567]年”) | セルA4の西暦2024年に「西暦2025年、西暦2026年または西暦2027年」が含まれているか(一致しているか) |
| =REGEXTEST(A5,”西暦202[567]年”) | セルA5の西暦2025年に 〃 |
| =REGEXTEST(A6,”西暦202[567]年”) | セルA6の西暦2026年に 〃 |
| =REGEXTEST(A7,”西暦202[567]年”) | セルA7の西暦2027年に 〃 |
| =REGEXTEST(A8,”西暦202[567]年”) | セルA8の西暦2028年に 〃 |
| =REGEXTEST(A9,”西暦202[567]年”) | セルA9の西暦2029年に 〃 |
| =REGEXTEST(A10,”西暦202[567]年”) | セルA10の西暦2030年に 〃 |
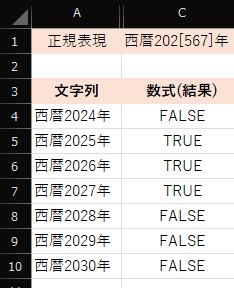
注 TRUE : 該当文字が含まれている、FALSE : 含まれていない
例 (セルA2の文字列)
当連結会計年度末の総資産は、前連結会計年度末に比べ53百万円減少し、8億26百万円となり
| 数式 | 問い |
| セルA4 =REGEXTEST(A2,”前”) | 文字 ‘前’ が含まれていますか? |
| =REGEXTEST(A2,”[0-9]”) | 数字が含まれていますか? |
| =REGEXTEST(A2,”[7-9]”) | 数字7から9が含まれていますか? |
| =REGEXTEST(A2,”[01234]”) | 数字0から4が含まれていますか? |
| =REGEXTEST(A2,”[あ-お]”) | 文字 ‘あ’から’お’ が含まれていますか? |
| =REGEXTEST(A2,”[た-の]”) | 文字 ‘た’から’の’ が含まれていますか? |

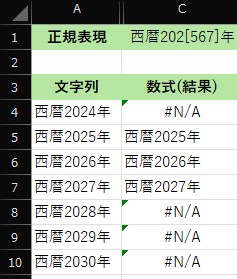
次の文字列から数値などを抽出する
REGEXEXTRACT 関数を使用すると、指定された正規表現に基づいて文字列からテキストを抽出できます。
REGEXEXTRACT(text, pattern, [return_mode], [case_sensitivity])
text : 対象テキスト
pattern : 正規表現
[return_mode] : 0: パターンに一致する最初の文字列を返します
1: パターンに一致するすべての文字列を配列として返します
2: 最初の一致からキャプチャ グループを配列として返す
[case_sensitivity] : 大文字小文字か
| 数式 | 問い |
| セルC4 =REGEXTEST(A4,”西暦202[567]年”) | セルA4の西暦2024年に「西暦2025年、西暦2026年または西暦2027年」が含まれていれば抽出 |
| =REGEXTEST(A5,”西暦202[567]年”) | セルA5の西暦2025年に 〃 |
| =REGEXTEST(A6,”西暦202[567]年”) | セルA6の西暦2026年に 〃 |
| =REGEXTEST(A7,”西暦202[567]年”) | セルA7の西暦2027年に 〃 |
| =REGEXTEST(A8,”西暦202[567]年”) | セルA8の西暦2028年に 〃 |
| =REGEXTEST(A9,”西暦202[567]年”) | セルA9の西暦2029年に 〃 |
| =REGEXTEST(A10,”西暦202[567]年”) | セルA10の西暦2030年に 〃 |


コメント